Lokale variasjoner i brukertilfredshet
Sammendrag
I denne artikkelen bruker vi flernivåanalyse til å se nærmere på NAV-kontorets betydning for brukernes tilfredshet med NAV. Data til analysen er hentet fra NAVs Personbrukerundersøkelse 2019. Ved å bruke flernivåanalyse kan vi med større presisjon si noe om hvorvidt det er egenskaper ved brukerne eller forhold ved NAV-kontoret som fører til lokale variasjoner i brukertilfredsheten enn vi kan ved bruk av vanlig lineær regresjon.
Vi finner at variasjonen i brukertilfredsheten i all hovedsak kan tilskrives trekk ved brukerne, det vi kaller sammensetningseffekter. Variasjonene mellom NAV-kontor betyr mindre. En vanlig feiltolkning av slike resultater er at NAV-kontoret ikke betyr noe for brukertilfredsheten, men vi argumenterer for at bildet er mer sammensatt. Årsaker til at det er lite variasjon i brukertilfredsheten mellom NAV-kontorene kan være at de er relativt standardiserte i sitt møte med brukerne. Samtidig kan det være at ulik praksis ikke nødvendigvis fører til ulikheter i brukertilfredsheten. To brukere med ellers like egenskaper kan være like fornøyde med NAV, selv om de har fått ulik innretning på oppfølging og tjenester. I analysene ser vi også nærmere på konkrete individ- og lokalnivåfaktorer som kan forklare variasjonen i brukertilfredsheten.
Et annet og ganske naturlig funn er at forhold ved NAV-kontoret betyr mer for de brukerne som har erfaring med oppfølging fra sitt lokale NAV-kontor, sammenlignet med de brukerne som kun har erfaring fra sentrale forvaltningsenheter.
Analysen viser at flernivåanalyse kan være nyttig dersom vi ønsker å si noe mer presist om organisasjonens rolle for det vi studerer, enten det gjelder brukerundersøkelser eller annen statistikk som kan tillegges en geografisk struktur. Slike analyser kan øke kunnskapen om det vi studerer og følgelig gi et bedre grunnlag for beslutninger og utviklingsarbeid. Dette demonstrerer og diskuterer vi nærmere i artikkelen.
Innledning
I denne artikkelen ser vi nærmere på NAV-kontorets betydning for brukertilfredsheten i NAV. Vi spør hvor stor andel av variasjonen i brukertilfredsheten som kan tilskrives den konteksten NAV-kontoret utgjør for brukerne, og bruker flernivåanalyse til å belyse dette. Mye av den arbeidsrettede brukeroppfølgingen skjer lokalt på NAV-kontoret, mens en del andre tjenester ytes fra sentrale enheter. Vi forventer derfor at den lokale konteksten kan tillegges mer forklaringskraft for de brukerne som har vært under oppfølging ved et lokalt NAV-kontor, sammenlignet med brukere som kun har vært i kontakt med sentrale enheter.
Artikkelen kan leses både tematisk og metodisk. Tematisk som et bidrag til økt kunnskap om brukertilfredshet i NAV, metodisk som en demonstrasjon på hvordan flernivåanalyse kan benyttes når vi står overfor data som kan tillegges en hierarkisk struktur.
I første del presenterer vi to begreper som er gjennomgående i artikkelen: sammensetning og kontekst. Deretter kommer vi nærmere inn på hvorfor det er interessant å studere lokalnivåets betydning i NAV-sammenheng. I tredje del gjennomgår vi et utvalg studier med liknende tilnærming, altså lokalnivåets betydning for det forholdet som studeres. Deretter beskriver vi den metodiske tilnærmingen, og i den femte delen gjengir vi resultatene fra flernivåanalysene. Vi avslutter med en oppsummering og diskusjon av hva funnene i artikkelen betyr for NAV.
Sammensetning eller kontekst?
To viktige begreper for å belyse tematikken er sammensetningseffekter og kontekstuelle effekter (se f.eks. Ballas og Tranmer 2011). Sammensetningseffekter har å gjøre med hvordan egenskaper ved individer påvirker et aggregert mål, i dette tilfellet brukertilfredsheten. Det betyr at personer med bestemte egenskaper kan påvirke tilfredsheten i enten positiv eller negativ retning. Egenskaper ved brukerne er ikke nødvendigvis likt geografisk fordelt. Eksempelvis har noen kommuner en høyere andel eldre i befolkningen enn andre, noe som kan påvirke den samlede tilfredsheten positivt siden alderspensjonister er blant de mest fornøyde av NAVs brukere (Nyberg mfl. 2019). Sammensetningseffekter er derfor effekter som i større grad kan tilskrives individuelle forhold, og ikke egenskaper ved lokalsamfunnet som sådan.
Kontekstuelle effekter dreier seg, på sin side, om forhold som påvirker individenes tilfredshet, men som ikke kan knyttes direkte til kjennetegn ved individet. Forholdet kan fortsatt utgå fra individer, men den samlede effekten må forstås på et annet nivå (Grimen 2004, s. 265–287). For eksempel kan arbeidsledighet forstås som en individuell situasjon, mens ledighetsnivået i et lokalsamfunn kan forstås som en kontekst. Da kan vi reise spørsmål ved om ledighet oppfattes som mindre vond blant individer som oppholder seg i omgivelser der det er høy arbeidsledighet (Clark 2003; referert i Ballas og Tranmer 2011; Heggebø og Elstad 2018). Kontekstuelle effekter kan også inkludere forhold som sosial eller økonomisk ulikhet, praktiske forhold som reisetider og tilgjengelighet til offentlige tjenester, samt forhold som kultur og holdninger. Forskjeller mellom NAV-kontorene, for eksempel i tilgjengelighet, organisering, kompetanse og oppfølgingstilbud, kan også tenkes å påvirke tilfredsheten og dermed utgjøre en slik kontekstuell effekt. Siden mange ulike aspekter kan inngå i konteksten, kan vi ikke på forhånd konkludere med at eventuelle variasjoner i brukertilfredshet på lokalnivå kun kan forklares med trekk ved NAV-kontoret, men må også ta høyde for at andre forhold i lokalsamfunnet spiller inn. Analysene nedenfor tyder imidlertid på at en slik tolkning er mulig. Vi benytter derfor begrepene NAV-kontor, lokalnivå og lokal kontekst om hverandre.
Selv om det teoretiske skillet mellom sammensetnings- og kontekstuelle effekter kanskje fremstår klart, kan en del av disse mulige effektene være diffuse og lite målbare. I en vanlig regresjonsanalyse kan det medføre at kontekstuelle forhold tillegges for stor vekt, dersom en ikke klarer å kontrollere for relevante sammensetningsfaktorer. Det oppstår dermed en situasjon hvor den kontekstuelle betydningen overvurderes; det som i metodelitteraturen kalles «økologiske feilslutninger» (Skog 2004). I artikkelen benytter vi derfor flernivåanalyse for å forsøke å skille mellom disse to typene effekter.
NAV som både en sentral og lokal organisasjon
NAV kan betraktes som både en nasjonal og en lokal organisasjon. Lover og regelverk for NAVs virke er nasjonale, med unntak av variasjoner i lokale føringer for sosialtjenesten og andre kommunale tjenester. NAV-kontorene er en del av en statlig styringslinje, men inngår samtidig i partnerskap med kommunene. Samlet sett står brukerne i møtet med NAV overfor sentrale og/eller lokale kontaktpunkter, avhengig av hvilken tjeneste brukerne benytter og hvilke ytelser de mottar.
Det vi kan kalle tradisjonelle «forvaltningstjenester» er i all hovedsak sentralisert, under NAV Arbeid og Ytelser, som ligger i en annen styringslinje enn NAV-kontorene. Dette er tjenester som i større grad er regelbundne og hvor det er mindre rom for skjønn (se f.eks. Molander 2016; Øverbye 2017). Saksbehandlingen er som oftest spesialisert, og sakene behandles i hovedsak uavhengig av brukerens bosted. Eksempelvis vil søknader om stønader (foreldrepenger, dagpenger, arbeidsavklaringspenger med mer) behandles i spesialiserte enheter uansett hvor i landet brukeren bor. Disse kan likevel ha et lokalt element i og med at grunnlaget for søknaden til eksempelvis arbeidsavklaringspenger og uføretrygd utarbeides lokalt.
På den andre siden, foregår det vi her kaller «oppfølgingstjenestene» i hovedsak lokalt på NAV-kontorene, både ved fysisk oppmøte, telefonkontakt, digital dialog og i arbeidsmarkedstiltak. Brukerne kan riktignok få enklere former for veiledning over telefon fra nasjonale enheter (NAV Kontaktsenter) eller på nett. Oppfølgingen fra NAV-kontorene dreier seg ofte om en mer utførlig utredning og veiledning av brukere inn mot arbeid eller annen aktivitet – altså oppgaver som krever mer personlig oppfølging av brukeren og hvor det er større behov og rom for å utøve skjønn. Vi kan derfor anta at det er mer variasjon her enn i forvaltningstjenestene.
NAV-kontorene ledes i et partnerskap mellom den enkelte kommune og den statlige delen av NAV ved NAV fylke (NAV-loven §13–14). En av hensiktene med partnerskapet er at NAV-kontorets virke skal tilpasses lokale behov og utfordringer. Denne tilpasningen henger sammen med ambisjonen om «myndige NAV-kontor» (St.meld. nr. 33. 2016). Selv om partnerskapet er likeverdig, er det funn som tyder på at staten dominerer partnerskapet (Fossestøl mfl. 2014).
En kan tenke seg at ulike mekanismer bidrar til likhet eller forskjeller mellom NAV-kontorene i deres møter med brukerne. Mekanismer som kan bidra til likhet inkluderer sentrale retningslinjer i form av tildelingsbrev og prioriteringer fra departementet, «veiledningsplattformen» og servicerutiner, nasjonal fordeling av ressurser, møter og informasjonsutveksling mellom kontorer på ulike arenaer og felles digitale løsninger.
Mekanismer som kan bidra til forskjeller er ulike måter å organisere og praktisere arbeidet på ved det enkelte kontor (Proba 2018), eller at fylker definerer mer detaljerte standarder for oppfølging på utvalgte områder (Kann og Åsland Lima 2015). Det enkelte fylke eller kontor kan også ha ulike tilganger og tilnærminger til tiltaksplasser. Utover det rent strukturelle kan en også tenke seg at ledelse, medarbeidere og kultur påvirker arbeidet lokalt på en måte som gjør at kontorene ikke er – eller ikke oppleves – som like (Bolman og Deal 2014). Vi kan heller ikke utelukke at variasjoner mellom NAV-kontor påvirkes av andre offentlige aktører, som helse- og skolevesen (f.eks. Arntzen og Grøgaard 2012; NIFU og Proba 2015).
Selv om brukerne i all hovedsak har krav på de samme tjenester uavhengig av bosted, er det altså flere årsaker til at de kan oppleve variasjoner i oppfølgingstjenestene avhengig av hvilket NAV-kontor de har dialog med og hvilket fylke dette kontoret tilhører. Samtidig kan vi anta at variasjonen er mindre i møtet med forvaltningstjenestene. Brukernes møte med NAV er dermed et interessant tema for flernivåanalyse, hvor det nettopp er mulig å anslå betydningen av slike variasjoner.
Med NAV som både en sentral og lokal organisasjon som utgangspunkt, ser vi nærmere på brukernes tilfredshet med NAVs tjenester. Brukertilfredshet inngår i styringsparameterne NAV er underlagt fra Arbeids- og sosialdepartementet, og tilfredse brukere er ett av hovedmålene i NAVs virksomhetsstrategi (ASD 2018; NAV 2019). Vi kan derfor anta at kontorene arbeider med brukertilfredsheten, at det er rom for ulike tilnærminger og at vi dermed kan avdekke systematiske variasjoner mellom lokalnivåene.
Artikkelens hovedanliggende er altså å studere forholdet mellom sammensetnings- og kontekstuelle effekter på brukertilfredsheten. Med bakgrunn i at NAV kan forstås som både en sentral og lokal organisasjon, forventer vi at (a) lokalnivået betyr mer for den generelle brukertilfredsheten for de brukerne som har hatt kontakt med NAV-kontoret, og at (b) variasjonen på lokalnivået er mer betydelig når brukerne evaluerer veiledningen de har fått på NAV-kontoret, enn når de evaluerer NAV generelt.
Tidligere studier av lokale variasjoner
Selv om mange samfunnsvitenskapelige arbeider tar for seg geografiske variasjoner, er det ikke utbredt å benytte flernivåanalyse for å skille mellom sammensetningseffekter og kontekstuelle effekter. I denne delen beskriver vi noen utvalgte studier, enten fordi de er metodisk interessante eller fordi de har direkte relevans for temaet brukertilfredshet.
Ballas og Tranmer (2011) og Duncan mfl. (1993) illustrerer godt fordelene ved flernivåanalyse. Begge demonstrerer at det i hovedsak er sammensetningseffekter, snarere enn kontekstuelle effekter, som forklarer geografiske variasjoner ved ulike fenomener. Ballas og Tranmer (2011) spør om tilfredshet med tilværelsen påvirkes av husholdningen en tilhører og geografisk tilhørighet. De finner at variasjonen i velvære i all hovedsak kan tillegges forhold ved individet (90 prosent), at en del kan tillegges husholdningen (10 prosent), men at ingen andel av variasjonen kan tilskrives den geografiske tilhørigheten.
Duncan mfl. (1993) studerer geografiske variasjoner i alkohol- og røykevaner blant briter. En «tom» flernivåanalyse (se Vedlegg 1) avdekker at 87 prosent av variasjonen i alkohol- og røykevaner skyldes forhold ved innbyggerne, mens 13 prosent kan tilskrives geografiske forhold. Når flere variabler introduseres i modellen, som alder og arbeidsmarkedsstatus, reduseres den geografiske betydningen ytterligere: til kun 4 prosent av variasjonen i røykevanene.
I Norge er det et knippe studier som benytter flernivåanalyse til å analysere ulike former for brukertilfredshet, hovedsakelig med data fra Innbyggerundersøkelsen (NSD 2017). Monkerud og Sørensen (2010) og Christensen og Midtbø (2011) studerer hva som påvirker innbyggernes tilfredshet med kommunale tjenester. Begge finner at lokalnivået står for en mindre andel av variansen i tilfredsheten (fra 2 til 12 prosent i ulike modeller). Generelt sett reduseres lokalnivåets betydning når det kontrolleres for både individuelle og kontekstuelle faktorer. Det er derfor, igjen, befolkningssammensetningen og i mindre grad de kontekstuelle faktorene som betyr mest for variasjonen i tilfredsheten. Det er samtidig interessant å notere at de to undersøkelsenes flernivåanalyser gir ulike utslag på befolkningsstørrelsens betydning for tilfredsheten med tjenestene. Det illustrerer at det er fruktbart å forsøke ulike oppsett og kombinasjoner av variabler i analysene.
Hovedinntrykket fra de nevnte studiene er altså at kontekstuelle faktorer betyr relativt lite sammenlignet med sammensetningsfaktorer. Det må imidlertid ikke tolkes som at lokale myndigheter betyr lite for tjenestetilfredsheten, men at det er få systematiske variasjoner mellom lokalnivåene etter at det tas høyde for individuelle kjennetegn ved respondentene (se f.eks. Hellevik 2011, s. 164–168). Siden vi gjør likelydende funn i vår analyse, kommer vi tilbake til mulige årsaker til dette i diskusjonen.
Metode og data
I denne delen kommer vi noe nærmere inn på fordelene med flernivåanalyse sammenlignet med vanlig lineær regresjon. Deretter omtaler vi surveydataene som ligger til grunn for analysen i denne artikkelen.
Fordelene med flernivåanalyse
I mange sammenhenger er det vanlig å aggregere individdata til et høyere nivå som kjennetegner individene, eksempelvis deres kommune- og fylkestilhørighet. De aggregerte indikatorene benyttes deretter til å sammenligne enheter på samme nivå, for eksempel NAV-kontor, og noen kan tolke de aggregerte dataene som et uttrykk for enhetenes prestasjoner. En slik tolkning avhenger imidlertid av at enhetene som nevnes påvirker individene – at de utgjør en relevant kontekst. Om ikke, står vi overfor en økologisk feilslutning (Skog 2004, s. 110), hvor forskjeller som egentlig skyldes sammensetningen av individnivået feilaktig benyttes til å si noe om egenskapene ved et høyere nivå.
Vanlig lineær regresjon brukes som oftest til å avdekke hvordan en eller flere uavhengige variabler påvirker en avhengig variabel, alt annet holdt likt (f.eks. Field 2009; Skog 2004). Estimatene beregnes for hver av de uavhengige variablene slik at summen av residualene (det uforklarte) i modellen minimeres. En av forutsetningene for modellen er at det er uavhengighet mellom residualene for den enkelte observasjon, med andre ord at studieobjektene ikke tilhører grupperinger som kan tenkes å påvirke resultatene. Denne forutsetningen regnes gjerne som oppfylt i undersøkelser hvor et tilfeldig utvalg ligger til grunn (Skog 2004).
I noen tilfeller vil det imidlertid være tvil om hvorvidt forutsetningen om restleddenes uavhengighet er oppfylt. Et eksempel er tidsseriedata, hvor data tilknyttet de samme personene registreres på ulike tidspunkter. Det kan også være tvil om uavhengigheten selv ved tilfeldige utvalg i enkeltundersøkelser: disse kan påvirkes av ulike grupperinger, som husholdning eller, som er aktuelt i denne artikkelen: geografi.
Flernivåanalyse kan benyttes til å undersøke om det foreligger strukturer i dataene – i vårt tilfelle geografiske nivåer – som påvirker residualene. Dersom det er slike strukturer, kan betydningen av disse estimeres og beskrives nærmere. Ved hjelp av flernivåanalyse kan vi altså si noe mer presist om forholdet mellom sammensetnings- og kontekstuelle effekter. Hvert nivås betydning for variasjonen måles med intraklassekorrelasjonen (ICC) i prosent. I Vedlegg 1 kommer vi noe nærmere inn på hvordan flernivåanalysen fungerer.
Data
For å beregne sammensetnings- og kontekstuelle effekter på brukertilfredshet, benytter vi surveydata fra Personbrukerundersøkelsen 2019. Vi benytter to spørsmål fra undersøkelsen til å måle henholdsvis generell tilfredshet og tilfredshet med veileder:
Tenk tilbake på dine erfaringer med NAVs service de siste seks måneder. Hvor fornøyd eller misfornøyd er du med den service du har fått hos NAV helhetlig sett? (generell tilfredshet)
Veiledningen jeg har fått i møte med ansatte på NAV-kontoret (tilfredshet med veiledning)
Sistnevnte spørsmål inngår i en matrise hvor respondenten blir spurt hvor fornøyd han eller hun er med ulike forhold. Begge spørsmål er besvart på en Likertskala fra 1 til 6, hvor 6 er høyeste skår.
For å avdekke om den geografiske betydningen er større når brukeren har hatt kontakt med et NAV-kontor enn når brukeren kun har hatt kontakt med en nasjonal enhet, er det behov for å skille mellom brukergrupper. Vi deler brukerne inn i to hovedgrupper, basert på om de har svart på spørsmål om veiledning ved NAV-kontoret og om de er i en av NAVs oppfølgingsgrupper (tabell 1). Siden de som benytter oppfølgingstjenester i stor grad også benytter forvaltningstjenester (f.eks. en person med nedsatt arbeidsevne som mottar arbeidsavklaringspenger), men ikke motsatt, er det vanskelig å skille ut en gruppe av betydelig størrelse med kun oppfølgingstjenester. Videre, antar vi at arbeidssøkere får noe mindre lokal oppfølging enn de andre nevnte gruppene, og vi estimerer derfor også en modell uten disse. Totalt har vi tre hovedgrupperinger av brukere: (1) Alle, (2) forvaltning og oppfølging, med og uten arbeidssøkere og (3) kun forvaltning.
NAVs Personbrukerundersøkelse
Dette er NAVs årlige brukerundersøkelse, hvor et tilfeldig utvalg personer som har hatt kontakt med NAV de siste månedene, svarer på spørsmål om sin erfaring med NAV.
I 2019 var 77 prosent av brukerne fornøyd med NAV generelt sett, mens 73 prosent var fornøyd med veiledningen de fikk i møte med ansatte fra NAV-kontorene.
Det er mottakere av alderspensjon, kontantstøtte, arbeidsavklaringspenger (AAP), barnetrygd og sykmeldte som er mest fornøyd, mens personer med nedsatt arbeidsevne (uten AAP) er blant de minst fornøyde.
Mer detaljer om brukertilfredsheten fordelt på de enkelte brukergruppene, metode og ytterligere funn er tilgjengelig i rapporten fra undersøkelsen (Nyberg mfl. 2019).
Alle |
Forvaltning og oppfølging |
Forvaltning |
|---|---|---|
Respondenter som har svart på spørsmål om generell tilfredshet, uansett brukergruppe |
Respondenter som i tillegg har svart på spørsmål om veiledningen ved NAV-kontoret og som var registrert som enten: Arbeidssøker Enslig forsørger (med overgangsstønad) Personer med nedsatt arbeidsevne (med og uten AAP) Sykmeldt (over 12 uker) |
Respondenter som ikke er i gruppen «Forvaltning og oppfølging» (f.eks. brukere som har søkt om alderspensjon, foreldrepenger og kontantstøtte) |
Kilde: NAV
I noen av flernivåmodellene vil vi inkludere uavhengige variabler på individ- og lokalnivå som av ulike årsaker kan tenkes å påvirke brukertilfredsheten og forholdet mellom sammensetnings- og kontekstuelle effekter. Variablene på individnivå er de samme som er registrert på respondentene i Personbrukerundersøkelsen, deriblant brukergruppe, alder, innvandrerbakgrunn, digitalt kompetansenivå og utdanningsnivå (se Vedlegg 2 i Nyberg mfl. 2019 for detaljer). Variablene på lokalnivå har vi hentet ut fra NAVs registerdata. Disse inkluderer forhold på lokalnivå som vi antar kan ha påvirkning på brukertilfredsheten, som befolkningsstørrelse, hvor stor andel NAVs prioriterte grupper utgjør av befolkningen, sykefravær blant ansatte på NAV-kontoret og arbeidsmarkeds- og uførestatistikk (ASD 2018; Ballas og Tranmer 2011; Bergh og Tjerbo 2013; Roaldsnes 2018). I Tabell 2 gir vi en beskrivelse av variablene.
Gjennomsnitt (std.avvik) |
|
|---|---|
Individnivå |
|
Over 30 år (0 = under 30 år) |
0,9 (0,3) |
Født i Norden (0 = ikke født i Norden) |
0,8 (0,4) |
Mann (0 = kvinne) |
0,4 (0,5) |
Digital kompetanse (skala fra 0 til 5, hvor 5 er høyest) |
2,8 (1,5) |
Utdanningsnivå (skala fra 1 til 5, hvor 5 er høyest) |
3,3 (1,4) |
Husholdningsinntekt i kroner (skala fra 1 til 5, hvor 5 er høyest) |
3,8 (1,7) |
Kjøretid fra bosted til NAV-kontor (antall minutter) |
10,2 (12,9) |
Lokalnivå |
|
Befolkning, 18–67 år, (antall) |
20 560 (18 545) |
Andel ungdom, 18–29 år (prosent av befolkningen) |
15,6 (2,7) |
Andel innvandrere (født utenfor Norden) i prosent av befolkningen |
12,6 (4,9) |
Andel arbeidssøkere og AAP-mottakere i prosent av befolkningenr |
7,5 (1,7) |
Andel uføre i prosent av befolkningen |
10,9 (3,1) |
Sykefravær ved NAV-kontoret i prosent |
7,9 (5,0) |
Kilde: NAV
Analyse og resultater
Vi utfører analysene i to deler. Først estimerer vi flere modeller uten forklaringsvariabler, såkalte «tomme» flernivåmodeller, for å belyse i hvor stor grad de ulike nivåene forklarer variasjonen i tilfredshet blant ulike brukergrupper. Disse modellene besvarer langt på vei våre forventninger knyttet til at lokale forhold betyr mer for de brukerne som har hatt kontakt med NAV-kontoret. For å undersøke forholdet mellom sammensetnings- og kontekstuell effekt nærmere, bygger vi deretter videre på den modellen hvor de lokale forholdene viser seg å bety mest, ved å legge til variabler på individ- og lokalnivå.
Tomme flernivåmodeller
Vi får en pekepinn på hvor stor andel av variasjonen i dataene som kan tillegges fylkesnivået, lokalnivået og individnivået ved å estimere «tomme» flernivåmodeller, altså modeller uten (uavhengige) forklaringsvariabler (se vedlegg 1). I tabell 3 viser vi fem tomme modeller, med ulike brukergrupper og ulike avhengige variabler. Konstantleddet blir i de tomme modellene et estimat på avhengig variabel; altså gjennomsnittet for brukertilfredsheten, angitt på en skala fra 1 til 6. Deretter vises den beregnede totale variansen for hvert av de tre nivåene. Intraklassekorrelasjonene (ICC) er andelen av variansen som tillegges det enkelte nivå og er gjengitt i prosent. Den er dermed et estimat på hvor stor andel av den totale variasjonen i brukertilfredsheten som forklares av fylkes- og lokalnivået. Det er denne vi er mest opptatt av i den første delen av analysen.
Modell 1 |
Modell 2 |
Modell 3 |
Modell 4 |
Modell 5 |
||||||
|---|---|---|---|---|---|---|---|---|---|---|
Avhengig variabel |
Generell tilfredshet |
Tilfredshet med veiledning |
||||||||
Utvalg |
Alle |
Forvaltning |
Oppfølging/ |
Oppfølging/ |
Oppfølging/ forvaltning u/ arbeidssøkere |
|||||
Konstantledd |
4,45 |
(0,02) |
4,46 |
(0,02) |
4,52 |
(0,03) |
4,53 |
(0,04) |
4,63 |
(0,04) |
Fylkesnivå, o2 |
0,00 |
(0,00) |
0,00 |
(0,00) |
0,00 |
(0,00) |
0,01 |
(0,00) |
0,00 |
(0,00) |
Lokalnivå, o2 |
0,01 |
(0,00) |
0,01 |
(0,00) |
0,03 |
(0,01) |
0,03 |
(0,01) |
0,07 |
(0,03) |
Individnivå, o2 |
2,08 |
(0,02) |
2,01 |
(0,02) |
2,09 |
(0,03) |
2,19 |
(0,03) |
2,07 |
(0,07) |
ICC fylkesnivå, % |
0,04 |
(0,10) |
0,11 |
(0,17) |
0,00 |
(0,00) |
0,27 |
(0,37) |
0,00 |
(0,00) |
ICC lokalnivå, % |
0,51 |
(0,28) |
0,37 |
(0,39) |
1,41 |
(0,94) |
1,80 |
(0,97) |
3,16 |
(1,47) |
Antall grupper, lokal- og fylkesnivå |
394, 18 |
372, 18 |
349, 18 |
350, 18 |
328, 18 |
|||||
Antall observasjoner |
9233 |
5423 |
2564 |
2586 |
1828 |
|||||
LR-test (konservativ), p |
0,06 |
0,45 |
0,18 |
0,05 |
0,02 |
|||||
ICC-estimatene, med unntak av fylkesnivået i Modell 1, 3 og 5, er signifikant forskjellig fra null (p<0,05).
Kilde: NAV
For det første forventet vi at lokalnivået betyr mer for tilfredsheten for de som har kontakt med NAV-kontoret, enn for de som kun har kontakt med en forvaltningsenhet. Forventningen synes bekreftet ved at den lokale andelen av variansen (ICC) er høyere i Modell 3, enn i Modell 1 og 2.
Vi antok at det generelle tilfredshetsspørsmålet fanget opp både nasjonal og lokal tilfredshet med NAV. Vår andre forventning var derfor at den lokale variasjonen er større når brukerne vurderer veiledningen de har fått på NAV-kontoret. Resultatene fra Modell 4 og 5 (tabell 3), hvor avhengig variabel er tilfredshet med veiledningen, peker i retning av en slik tendens. Her er andelen av variasjonen som tillegges lokalnivået høyere enn i de tre første modellene. Andelen er høyere for den gruppen som vi antar har mest kontakt med NAV-kontoret – altså oppfølgingsgruppen uten arbeidssøkere i Modell 5. Her er lokalnivåets andel av variasjonen 3,2 prosent (med en usikkerhet på mellom 1,3 og 7,7). Vi får også en noe høyere ICC dersom vi fjerner sykmeldte fra utvalget, da en del av disse trolig får oppfølging fra helsevesenet i større grad enn fra NAV (modell ikke vist her). Ut fra dette synes også den andre forventningen bekreftet. Det er altså en tendens til at den konteksten som lokalnivået utgjør, betyr mer, jo mer kontakt brukerne har med NAV-kontoret. Betydningen synes imidlertid som liten, noe vi kommer tilbake til i diskusjonen.
Ofte er det større interesse for hvordan bestemte enheter skårer, snarere enn total varians, og vi vil illustrere hvordan flernivåanalysen kan benyttes til å belyse dette. Vi bruker de estimerte gjennomsnittsverdiene for det enkelte lokalnivå fra flernivåmodellen og sammenligner disse med resultatene vi ville fått uten bruk av flernivåanalyse (se mer om «empirical Bayes» i vedlegg 1). Starten på pilene i figur 1 er det estimerte gjennomsnittet i tilfredsheten for hvert lokalnivå, etter en vanlig regresjon som kun inneholder lokalnivå som uavhengig dummyvariabel (modellen ikke gjengitt her). Enden på pilene er estimatene fra en flernivåanalyse tilsvarende den i Modell 5, men for enkelthets skyld uten fylkesnivået. Det fremgår at variasjonen mellom de ulike lokalnivåene blir mindre når vi bruker estimatene fra flernivåmodellen.
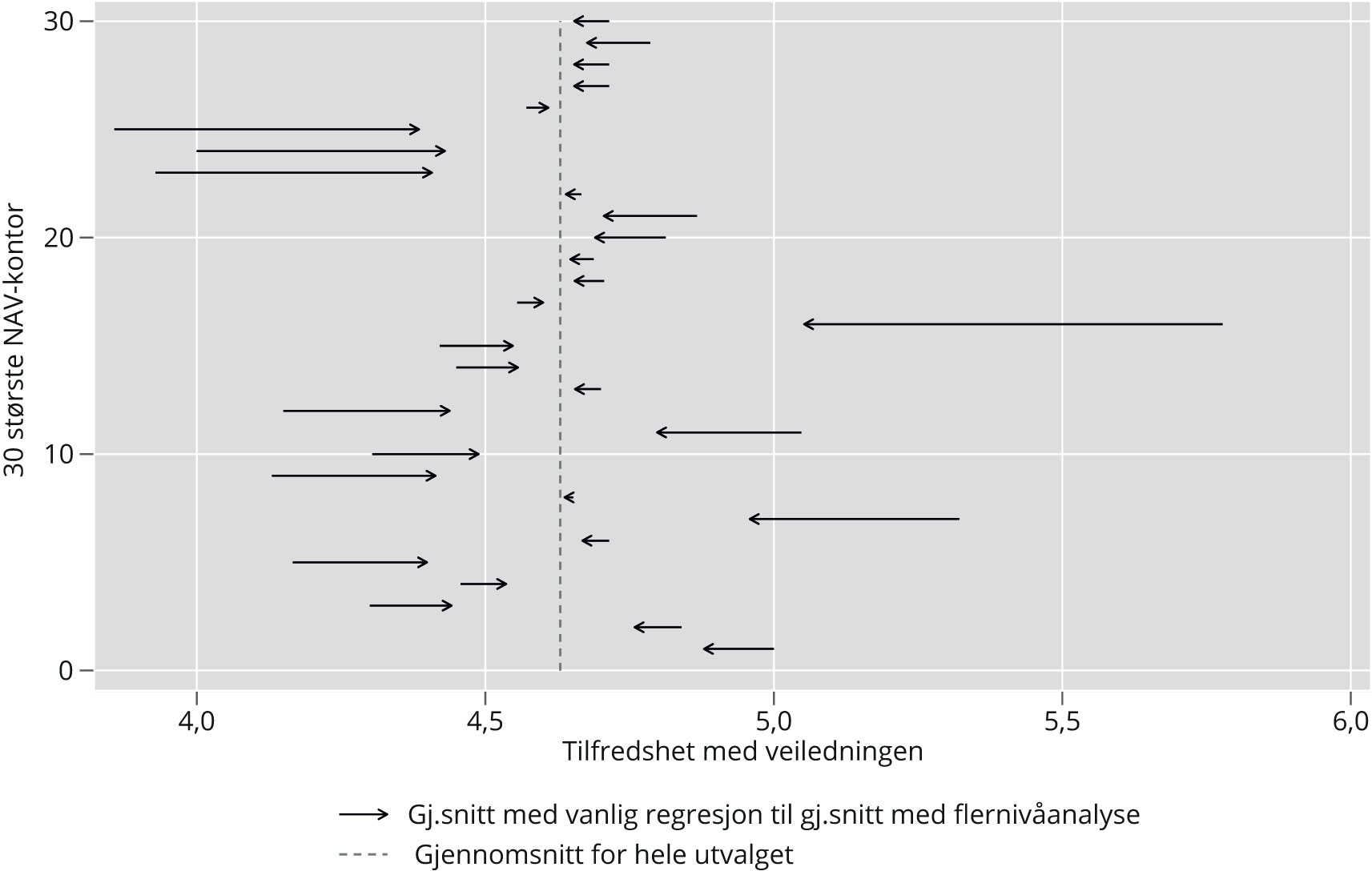
Figur 1: Estimert gjennomsnittlig tilfredshet per 30 største NAV-kontor (etter antall respondenter) med vanlig lineær regresjon og flernivåanalyse.
Kilde: NAV
Øvelsen viser at vi uten flernivåanalyse kan stå i større fare for å feilaktig konkludere at ett kontor er «bedre» enn et annet på brukertilfredshet. Resultatene fra vanlig regresjon vil trolig i større grad være «belemret» med sammensetningseffekter, mens resultatene fra flernivåanalysen i større grad kan tolkes som å representere kontekstuelle effekter. Likevel er det fortsatt forskjeller mellom lokalnivåene også i estimatene fra flernivåanalysen. I dette tilfellet vil vi imidlertid nevne at usikkerheten er relativt stor grunnet få respondenter (mellom 14 og 64 for lokalnivåene vist her), noe som også må hensyntas om en skal trekke slutninger om forskjeller mellom spesifikke enheter.
Videre modellering med individ- og lokalnivåvariabler
Hittil har vi vist at det kan være hensiktsmessig å benytte flernivåmodeller i analyser av brukertilfredshet, spesielt når bruker har kontakt med lokalkontoret. Vi bygger nå videre på Modell 5 fra tabell 3 ved å legge inn konkrete påvirkningsvariabler. For enkelthets skyld ser vi nå bort fra fylkesnivået og inkluderer kun lokalnivået. Denne forenklede tomme tonivåmodellen vises i tabell 4 som Modell 6.
Modell 6 |
Modell 7 |
Modell 8 |
Modell 9 |
|||||
|---|---|---|---|---|---|---|---|---|
Inkluderte variabler |
Tom |
Individ |
Lokalnivå |
Begge |
||||
Individvariabler |
||||||||
Over 30 år |
0,38*** |
(0,12) |
0,36*** |
(0,12) |
||||
Brukergruppe (enslig forsørger med overgangsstønad er base) |
||||||||
Nedsatt arbeidsevne (uten AAP) |
-0,39* |
(0,20) |
-0,39* |
(0,20) |
||||
Nedsatt arbeidsevne (med AAP) |
0,13 |
(0,19) |
0,12 |
(0,19) |
||||
Sykmeldte (over 12 uker) |
-0,02 |
(0,19) |
-0,02 |
(0,19) |
||||
Født i Norden |
-0,08 |
(0,09) |
-0,1 |
(0,09) |
||||
Mann |
-0,07 |
(0,07) |
-0,08 |
(0,07) |
||||
Digital kompetanse |
0,28*** |
(0,08) |
0,29*** |
(0,08) |
||||
Digital kompetanse, kvadrert |
-0,06*** |
(0,01) |
-0,06*** |
(0,01) |
||||
Utdanningsnivå |
-0,04* |
(0,03) |
-0,04* |
(0,03) |
||||
Husholdningsinntekt |
0,42*** |
(0,13) |
0,42*** |
(0,13) |
||||
Husholdningsinntekt, kvadrert |
-0,05*** |
(0,02) |
-0,05*** |
(0,02) |
||||
Kjøretid fra bosted til NAV-kontor, minutter |
0,00 |
(0,00) |
0,00 |
(0,00) |
||||
Lokalnivåvariabler |
||||||||
Befolkning 18–67, antall |
0,00 |
(0,00) |
0,00 |
(0,00) |
||||
Ungdom i prosent av befolkningen |
-0,04** |
(0,02) |
-0,03** |
(0,02) |
||||
Innvandrere i prosent av befolkningen |
-0,02** |
(0,01) |
-0,02** |
(0,01) |
||||
Andel arbeidssøkere og AAP-mottakere |
0,03 |
(0,03) |
0,03 |
(0,03) |
||||
Andel uføre |
-0,02 |
(0,02) |
-0,02 |
(0,02) |
||||
Sykefravær ved NAV-kontoret |
0,00 |
(0,01) |
0,00 |
(0,01) |
||||
Konstantledd |
4,63 |
(0,04) |
3,56 |
(0,26) |
5,36 |
(0,35) |
4,25 |
(0,44) |
Lokalnivå, σo2 |
0,06 |
(0,02) |
0,04 |
(0,01) |
0,05 |
(0,02) |
0,04 |
(0,01) |
Individnivå, oσ2 |
2,07 |
(0,04) |
1,98 |
(0,04) |
2,07 |
(0,04) |
1,98 |
(0,04) |
ICC lokalnivå, % |
3,00 |
(1,45) |
2,19 |
(1,28) |
2,54 |
(1,37) |
1,82 |
(1,25) |
R2 lokalnivå |
0,31 |
0,16 |
0,42 |
|||||
R2 individnivå |
0,04 |
0,00 |
0,04 |
|||||
R2 totalt |
0,05 |
0,01 |
0,05 |
|||||
Antall observasjoner: 1811. Antall grupper: 319. * p < 0,10, ** p < 0,05, *** p < 0,01.
Kilde: NAV
I tabell 4 gjengir vi resultatene fra tre ulike flernivåmodeller, spesifisert med flere uavhengige (fixed) variabler, for å undersøke forholdet mellom sammensetning og kontekst videre. Modell 7 og 8 inkluderer variabler for henholdsvis individ og lokalnivå, mens Modell 9 gjengir en «full» modell med variabler fra begge nivå.
Tabell 4 inneholder i tillegg tre indikatorer for forklaringskraften (R 2) i Modell 7 til 9. Denne beregnes ut fra hvor mye variansen reduseres i den enkelte modell, sammenlignet med Modell 6. Vi kan derfor beregne total forklart varians og den forklarte variansen for hvert av nivåene (de tre første formlene i LaHuis mfl. 2014; se også Mehmetoglu og Jakobsen 2017). Disse estimatene kan i utgangspunktet forstås på samme måte som i en vanlig regresjon; som andelen forklart varians. Den forklarte variansen for de enkelte nivåene – spesielt for lokalnivået – må imidlertid tolkes med forsiktighet, siden både variansen som beregnes for det enkelte nivå i den tomme modellen og forholdet mellom disse (ICC) kan endres når det tilføres ny informasjon i form av uavhengige variabler (LaHuis mfl. 2014). Nivåestimatene for R 2 må derfor ses som en pekepinn, mens den totale R 2 kan tolkes mer bokstavelig.
Modell 7 inneholder kun variabler på individnivå. Vi ser blant annet at tilfredsheten med veiledningen øker med alder, og at brukere som er registrert med nedsatt arbeidsevne (uten AAP) er noe mindre fornøyde. Digital kompetanse og husholdningsinntekt påvirker tilfredsheten i form av en «omvendt u», hvor de som er midt på skalaen er mer tilfredse med veiledningen enn de som er i topp og bunn. Samtidig er det en tendens til at de med høyere utdanningsnivå er mindre fornøyd. Altså virker «gjennomsnittsbrukeren» til å være mer fornøyd enn andre. Den beregnede avstanden fra brukers bosted til nærmeste NAV-kontor har ikke sammenheng med tilfredsheten. Funnene likner på resultatene i hovedrapporten fra Personbrukerundersøkelsen (Nyberg mfl. 2019), og omtales derfor ikke nærmere her.
ICC for lokalnivået reduseres noe i Modell 7 i forhold til Modell 6, trolig fordi noen av individvariablene også reflekterer egenskaper ved lokalnivået. Dette gjenspeiles i R2 for lokalnivå, som indikerer at 31 prosent av variansen i lokalnivået fanges opp i denne modellen. Som nevnt, må R 2 på lokalnivå tolkes med stor forsiktighet. Vi kan imidlertid med grunnlag i disse estimatene påstå at individvariablene fanger opp både sammensetnings- og konteksteffekter. R 2 på individnivå og totalt indikerer at Modell 7 forklarer 4 prosent av variansen i dataene på individnivået og 5 prosent totalt. Forklaringskraften til modellen i sin helhet er derfor svak.
I Modell 8 inkluderte vi kun variabler knyttet til lokalnivå. Befolkningsstørrelse – og dermed grovt sett størrelsen på NAV-kontoret – synes ikke å ha betydning for tilfredsheten. Sykefravær ved kontoret, andel brukere med oppfølgingsbehov i befolkningen og andel uføre påvirker heller ikke tilfredsheten ifølge modellen. Vi fant imidlertid at både andelen ungdom og andelen innvandrere (målt som personer født utenfor Norden) hadde en liten, men signifikant negativ sammenheng med tilfredsheten. Høye andeler av ungdom og innvandrere forekommer ofte samtidig og er knyttet til større byer. Samtidig er dette prioriterte målgrupper for NAV. Det er dermed flere mulige mekanismer som kan forklare en slik effekt. Eksempelvis kan det tenkes at kontorer som har en høy andel brukere som skal prioriteres (ungdom og innvandrere, se ASD 2018) får redusert kapasitet til oppfølging sammenlignet med andre kontorer. Det kan også tenkes at effektene representerer noe mer underliggende, eksempelvis knyttet til urbanitet, som vi ikke klarer å fange opp slik modellene er satt opp her.
Om vi skal tolke R2 for lokalnivået i Modell 8 bokstavelig, blir en vesentlig del – 16 prosent – av variansen beregnet i den tomme modellen forklart med disse variablene. Samtidig kan den lave R2 for individnivået tolkes som at modellen kun så vidt berører sammensetningseffekter og at vi her hovedsakelig har å gjøre med kontekstuelle effekter. Totalt sett har modellen svært liten forklaringskraft, med en total R2 beregnet til 1 prosent.
I Modell 9 gjengir vi den «fulle» modellen, inkludert både individ- og lokalnivåvariabler. Estimatene for de enkelte variablene er omtrent de samme som i de foregående modellene. Det er verdt å bemerke at de individuelle effektene og lokalnivåeffektene knyttet til ungdom og innvandring består. Det tyder på at disse effektene dreier seg om både sammensetning og kontekst. Med andre ord, kan vi si at den negative effekten av høy andel ungdom og innvandrere består, selv etter at det samme kontrolleres for på individnivå. Om vi igjen skal tolke R2 for lokalnivået bokstavelig, forklarer denne en høy andel – 42 prosent – av den estimerte variansen i den tomme modellen. Vi må imidlertid påpeke at den totale R2 fortsatt ligger på 5 prosent og at den kontekstuelle betydningen av lokalnivået, som målt i ICC, nå er redusert til 1,8 prosent. Hovedinntrykket er derfor at lokalnivåets betydning reduseres når modellen «tilføres» informasjon i form av flere uavhengige variabler og at lokalnivåvariablene ikke bidrar nevneverdig til å øke modellens totale forklaringskraft.
Oppsummering og diskusjon
I artikkelen har vi benyttet flernivåanalyse til å undersøke brukertilfredsheten med NAV. Hovedfunnet er at variasjonen i brukertilfredsheten i all hovedsak kan tilskrives trekk ved brukerne. Variasjonene mellom NAV-kontor betyr mindre. Vi vil først oppsummere og knytte noen kommentarer til selve funnene. Deretter drøfter vi generelle implikasjoner fra studien.
NAV-kontorene påvirker variasjonen i brukertilfredsheten – men kjennetegn ved brukerne betyr mest
NAVs brukere kan deles inn i de som får forvaltningstjenester fra sentrale enheter i NAV og de som får oppfølgingstjenester fra sitt lokale NAV-kontor. Disse brukergruppene gir mulighet til å studere i hvilken grad NAV-kontoret påvirker tilfredsheten med NAVs tjenester. Vi hadde to spesifikke forventninger til studien: a) at den lokale variasjonen i den generelle brukertilfredsheten ville være større for brukere som har hatt kontakt med NAV-kontoret, enn for brukere med erfaring kun fra sentrale enheter og b) at det ville være større lokal variasjon i brukernes tilfredshet med veiledningen på NAV-kontoret sammenlignet med den generelle brukertilfredsheten. Vi forventet altså at betydningen av den lokale konteksten ville være større, jo mer brukerne har hatt å gjøre med NAV-kontoret.
I analysene fremkommer det at andelen variasjon som tillegges konteksten, altså lokalnivået, er større for de brukerne som er under oppfølging enn for de brukerne som kun hadde erfaring med forvaltningstjenestene. Dette bekrefter forventningene om lokalnivåets betydning. Siden vi har denne konkrete sammenligningen mellom sentral og lokal kontakt, kan vi også langt på vei påstå at det er forhold på selve NAV-kontoret, snarere enn andre egenskaper ved lokalsamfunnet, som står for disse systematiske forskjellene.
Resultatene viser med andre ord at NAV-kontorets arbeid betyr noe for tilfredsheten, og det er dermed i tråd med det som kanskje vil være «gjengs» oppfatning. Det som derimot strider mot «allmenne» antakelser, er at NAV-kontoret innsats tilsynelatende betyr lite: kun 3,2 prosent av andelen av variasjonen på nivået kan tilskrives denne konteksten. Motsatt, kan vi altså si at sammensetningseffekter, som tilskrives 96,8 prosent av variasjonen, betyr desidert mest. Det er med andre ord forhold ved brukerne som er mest avgjørende for variasjonen i brukertilfredsheten.
Andelen av variasjonen som tilskrives konteksten er i nederste sjikt sammenlignet med studiene referert til over (Ballas og Tranmer 2011; Christensen og Midtbø 2011; Duncan mfl. 1993; Monkerud og Sørensen 2010). Det må imidlertid ikke forstås som at NAV-kontorene i praksis er ubetydelige for brukertilfredsheten, noe som er en vanlig feiltolkning av slike resultater (se f.eks. Hellevik 2011, s. 164–168). Det er minst tre årsaker til at NAV-kontorets andel av variasjonen er lav. For det første, vil andelene fra flernivåanalysen være en sammenligning mellom variasjonen som kan tillegges lokal- og individnivå. Selv om vi kan dele brukerne inn i ulike kategorier, kan det innenfor kategoriene være stor forskjell på brukerne som ikke lar seg måle på en god måte. Det er naturlig at slike store forskjeller mellom mennesker utgjør det meste av variasjonen i dataene.
For det andre, kan den lave andelen være et uttrykk for at NAV-kontorene er relativt standardiserte i møte med brukerne. Mekanismer som kan bidra til likhet i brukermøtene inkluderer lovverk og sentrale retningslinjer i form av for eksempel «veiledningsplattformen», intern ressursfordeling, møter og informasjonsutveksling mellom kontorer på ulike arenaer og felles digitale løsninger som både veiledere og brukere må benytte. Disse mekanismene kan være motivert av et ønske om å finne «best practice», men også en forventning blant politikere og innbyggere om at velferdstjenestene skal være mest mulig like, uansett hvilket forvaltningsnivå som har ansvaret (Grønlie 2004). Kanskje er også dette årsaken til at nær sagt ingen andel av variasjonen kan tillegges fylkesnivået: det kan tenkes at fylkene fungerer som en iverksetter av nasjonale rammer snarere enn at de bidrar til forskjeller mellom fylkene.
Selv om mange av rammene for brukeroppfølgingen er lagt er det, som vi har argumentert for tidligere i artikkelen, trolig fortsatt et betydelig handlingsrom for tilpasninger til lokale og individuelle forhold. Vårt tredje poeng er likevel at disse variasjonene ikke nødvendigvis reflekteres i brukertilfredsheten: det er fullt mulig å tenke seg at to brukere med ellers like egenskaper kan være like fornøyde med NAV, selv om de har fått ulik innretning på oppfølging og tjenester. Tilfredshet er tross alt et lineært mål på oppfatningen av tjenesten, ikke et mål på innretning.
Det er altså flere mulige årsaker til at NAV-kontorets andel av variasjonen er lav, som kan ha sine naturlige forklaringer relatert til individ, organisasjon og hvor godt tilfredshetsbegrepet er til å fange opp variasjon.
I de videre analysene «fyller» vi opp flernivåmodellen med variabler på individ- og lokalnivå. Vi gjør et interessant funn i form av at en høy andel av NAVs prioriterte grupper – ungdom og innvandrere – i befolkningen synes å danne en kontekst som påvirker brukertilfredsheten negativt. Det kan dreie seg om at en høy andel prioriterte grupper påvirker brukertilfredsheten ved at NAV-kontorets kapasitet til oppfølging reduseres. Vi kan imidlertid ikke utelukke at funnet dreier seg om noe mer underliggende knyttet til urbanitet som ikke fanges opp i våre analyser. Vi finner også, i tråd med tidligere analyser (Nyberg mfl. 2019), at det er flere kjennetegn ved individet som påvirker brukertilfredsheten. Eksempelvis har alder, digital kompetanse, inntekt og hvilke ordninger brukerne er tilknyttet, sammenheng med brukertilfredsheten. Dette er kjennetegn som har størst sammenheng med sammensetningseffektene og som forklarer noe mer av variasjonen i brukertilfredsheten enn de kontekstuelle faktorene. Totalt sett forklarer imidlertid påvirkningsfaktorene relativt lite av variasjonen i brukertilfredsheten.
I sum synes flernivåanalysen å være en fruktbar tilnærming for å øke kunnskapen om ulike nivåer og forholdet mellom sammensetnings- og kontekstuelle effekter. Vi vil likevel trekke frem tre svakheter og en betenkning med analysen. En forutsetning for å undersøke betydningen av ulike nivåer i et hierarki, er at vi spesifiserer de nivåer som vi mener utgjør en relevant kontekst for individet. I artikkelen har vi benyttet NAVs organisasjonsstruktur, men kun «i grovt». Det er sannsynlig at den enkelte veileder utgjør en mer relevant kontekst for brukeren enn det mer «abstrakte» NAV-kontoret og at et slikt nivå ville økt den kontekstuelle betydningen (Lipsky 2010). Vi kan også tenke oss andre relevante kontekster som ikke er tatt høyde for, eksempelvis forhold innad eller på tvers av kommunegrenser eller brukernes sosiale nettverk. En annen svakhet er at vi ikke fullt ut kjenner til hvor mye kontakt respondentene har hatt med veileder på NAV-kontoret. Mer kontakt kan tenkes å øke den lokale betydningen. Den tredje svakheten er relatert til den lave forklaringskraften den «fulle» modellen har. Det betyr at analysen trolig kunne vært tjent med flere forklaringsvariabler. En spesielt interessant variabel kunne vært den interne ressursfordelingen i NAV, siden slike økonomiske aspekter synes å gjøre utslag i lignende studier (Christensen og Midtbø 2011; Monkerud og Sørensen 2010). Av praktiske årsaker inkluderte vi ikke slike variabler i analysen.
Vår betenkning bunner i at vi skiller relativt skarpt mellom sammensetnings- og kontekstuelle effekter uten å ta hensyn til om konteksten påvirker hvordan sammensetningen ble til. I vår analyse benytter vi et tverrsnitt på et gitt punkt i tid, uten å stille spørsmål ved om det er egenskaper ved konteksten (NAV-kontorets arbeid og andre faktorer ved lokalsamfunnet) som bidrar til sammensetningen. Eksempelvis kan det tenkes at urbane områder tiltrekker seg personer med visse kjennetegn, og derfor at konteksten påvirker sammensetningen over tid. Det er vanskelig å se for seg at våre analyseresultater ville blitt nevneverdig annerledes selv om vi tok høyde for dette – men det er et interessant spørsmål å reflektere over når vi diskuterer skillet mellom sammensetning og kontekst.
Mulige implikasjoner for NAVs arbeid
Funnene i artikkelen viser at flernivåanalyse er fruktbart når vi skal studere lokale variasjoner. Dersom vi ønsker å si noe mer presist om betydningen av arbeidet i en organisasjon for det vi studerer, synes det verdifullt å kunne skille mellom sammensetnings- og kontekstuelle effekter. Fra et organisasjonsperspektiv er det ofte nettopp betydningen av konteksten vi er ute etter: hva er organisasjonens rolle? Ofte er det også av interesse å kunne peke på forskjeller mellom bestemte enheter.
I tillegg til at vi sammenligner den generelle betydningen av sammensetning og kontekst, demonstrerer vi hvordan den kontekstuelle effekten som bestemte enheter utgjør, kan undersøkes og sammenlignes. Det gjør vi ved å hente gjennomsnittsestimatene for hvert NAV-kontor ut fra analysen (figur 1). Vi sitter følgelig igjen med mer av den «rene» effekten som et bestemt NAV-kontor utgjør for brukertilfredsheten. Dersom vi skal kunne påstå at ett NAV-kontor har mer fornøyde brukere enn et annet – og at dette skyldes forhold ved NAV-kontoret – er det dette estimatet vi bør bruke. Denne tilnærmingen bidrar til mer kunnskap om hvorvidt ulikheter mellom enheter skyldes sammensetningen blant brukerne eller de enhetene de forholder seg til. Dette er eksempelvis uklart når vi presenterer den fylkesvise variasjonen i brukertilfredsheten i hovedrapporten fra brukerundersøkelsene (Nyberg mfl. 2019). I rapporten har vi ikke grunnlag for å si om disse variasjonene i hovedsak skyldes egenskaper ved brukerne eller ved fylkene, og noen vil derfor kunne tolke dette som at det er NAV-fylkene som påvirker brukertilfredsheten. Eller med andre ord: de ville begått en feilslutning, fordi vi i denne artikkelen finner at de geografiske forskjellene først og fremst skyldes sammensetningseffekter, ikke kontekstuelle effekter.
Mange av NAVs statistikker, både offisielle og interne, fordeler indikatorer på NAVs ulike styringslinjer og disse kan være bakgrunn for viktige samtaler og beslutninger som berører utviklingsarbeidet i NAV. En del av disse statistikkene, inkludert resultatene fra brukerundersøkelsene, inngår også som styringsparametere. Følgelig kan flernivåanalyse være aktuelt i mange tilfeller.
I mange tilfeller vil det imidlertid ikke være nødvendig å skille mellom sammensetnings- og kontekstuelle effekter. Lokale variasjoner kan være av interesse uansett. Det at noe først og fremst bør forstås som en sammensetningseffekt, betyr ikke at NAV kan innta en passiv rolle. Eksempelvis kan vi tenke oss at brukertilfredshet må tas på alvor, selv om mye av variasjonen kan tilskrives sammensetningseffekter. Kunnskap om den kontekstuelle betydningen vil imidlertid kunne være viktig for å peke på i hvor grad kontekstuelle faktorer, som NAVs arbeid, spiller inn og for å bedre kunne sammenligne innsatsen mellom ulike NAV-kontor.
Referanser
Arntzen, Annett og Jens B. Grøgaard (2012) «Idealer og realiteter i samarbeid mellom Nav og Oppfølgingstjenesten». Tidsskrift for velferdsforskning, 15 (4), 250–262.
ASD (2018) Tildelingsbrev 2018. Oslo: Arbeids- og sosialdepartementet. Tilgjengelig fra https://www.nav.no/no/NAV+og+samfunn/Om+NAV/Fakta+om+NAV/tildelingsbrev
Ballas, Dimitris og Mark Tranmer (2011) «Happy People or Happy Places? A Multilevel Modeling Approach to the Analysis of Happiness and Well-Being». International Regional Science Review, 35 (1), 70–102.
Bergh, Johannes og Trond Tjerbo (2013) «Betingelser for god demokratisk styring: En statistisk analyse». I Marte Winsvold (red.) Veien til god lokaldemokratisk styring. Oslo: NIBR.
Bolman, Lee G. og Terrence E. Deal (2014) Nytt perspektiv på organisasjon og ledelse (Kari Marie Thorbjørnsen, Overs., 5. utg.). Oslo: Gyldendal akademisk.
Christensen, Dag Arne og Tor Midtbø (2011) Tilfredshet med kommunale velferdstjenester: Har velferdstjenestene noe å si? (Notat 2–2011). Bergen: Uni Rokkansenteret.
Clark, Andrew E. (2003) «Unemployment as a Social Norm: Psychological Evidence From Panel Data». Journal of Labor Economics, 21, 324–351.
Duncan, Craig, Kelvin Jones og Graham Moon (1993) «Do Places Matter? A Multi-Level Analysis of Regional Variations in Health-Related Behaviour in Britain». Social Science & Medicine, 37 (6), 725–733.
Field, Andy (2009) Discovering Statistics using SPSS (3. utg.). London: Sage.
Fossestøl, Knut, Eric Breit og Elin Borg (2014) NAV-reformen 2014: En oppfølgingsstudie av lokalkontorenes organisering etter innholdsreformen (AFI-rapport 13). Oslo: Høgskolen i Oslo og Akershus.
Grimen, Harald (2004) Samfunnsvitenskapelige tenkemåter. Oslo: Universitetsforlaget.
Grønlie, Tore (2004) «Fra velferdskommune til velferdsstat - hundre års velferdsvekst fra lokalisme til statsdominans». Historisk tidsskrift, 83, 633–649.
Heggebø, Kristian og Jon Ivar Elstad (2018) «Is it Easier to Be Unemployed When the Experience Is More Widely Shared? Effects of Unemployment on Self-rated Health in 25 European Countries with Diverging Macroeconomic Conditions». European Sociological Review, 34 (1), 22–39.
Hellevik, Ottar (2011) Mål og mening: Om feiltolking av meningsmålinger. Oslo: Universitetsforlaget.
Kann, Inger-Cathrine og Ivar Andreas Åsland Lima (2015) «Tiltak i NAV Hedmark ga færre nye mottakere av arbeidsavklaringspenger». Arbeid og velferd (2), 77–94.
LaHuis, David M., Michael J. Hartman, Shotaro Hakoyama og Patrick C. Clark (2014) «Explained Variance Measures for Multilevel Models». Organizational Research Methods, 17 (4), 433–451.
Lipsky, Michael (2010) Street level bureaucracy: dilemmas of the individual in public services. New York: Russell Sage Foundation.
Mehmetoglu, Mehmet og Tor Georg Jakobsen (2017) Applied Statistics in Stata. London: Sage.
Molander, Anders (2016) Discretion in the Welfare State: Social rights and professional judgment. London & New York: Routledge.
Monkerud, Lars C. og Rune J. Sørensen (2010) «Smått og godt?». Norsk statsvitenskapelig tidsskrift, 26 (4), 265–296.
NAV (2019) NAVs virksomhetsstrategi. Oslo: Arbeids- og velferdsdirektoratet.
NIFU og Proba (2015) Samarbeid mellom fylkeskommunen og NAV om videregående opplæring for voksne arbeidssøkere (Rapport 2015–04).
NSD (2017) Innbyggerundersøkelsen. Tilgjengelig fra: https://nsd.no/nsddata/serier/innbyggerundersokelsen.html (Hentet: 8. aug 2019).
Nyberg, Tor Erik, Anders Thorgersen, Jørgen Holbæk-Johansen, Stine Rrenate Otterbekk og Sverre Friis-Petersen (2019) NAVs personbrukerundersøkelse 2019: resultater og påvirkningsfaktorer (Rapport-serie 4/2019). Arbeids- og velferdsdirektoratet.
Proba (2018) Organisering og praktisering av ungdomsarbeid ved seks NAV-kontorer.
Roaldsnes, Andreas (2018) «Mål- og resultatstyring i NAV - kan det bidra til å få flere personer med nedsatt arbeidsevne i arbeid?». Arbeid og velferd (1), 57–80.
Skog, Ole-Jørgen (2004) Å forklare sosiale fenomener: en regresjonsbasert tilnærming (2. utg.). Oslo: Gyldendal Akademisk.
Snijders, Tom A. B. og Roel J. Bosker (2012) Multilevel analysis: An Introduction to Basic and Advanced Multilevel Modeling (2. utg.). London: Sage.
St.meld. nr. 33. (2016) NAV i en ny tid - for arbeid og aktivitet. Oslo: Arbeids- og sosialdepartementet.
StataCorp (2017a) Likelihood-ratio test after estimation. College Station, Tex: StataCorp.
StataCorp (2017b) Mixed Postestimation. College Station, Tex: StataCorp.
Steenbergen, Marco R. (2012) Hierarchical Linear Models for Electoral Research. Tilgjengelig fra: https://www.exeter.ac.uk/media/universityofexeter/elecdem/pdfs/istanbulwkspjan2012/ Hierarchical_Linear_Models_for_Electoral_Research_A_worked_example_in_Stata.pdf (Hentet: 9. des 2019).
Strabac, Zan (2012) «Flernivåanalyse». I Terja A. Eikemo og Tommy H. Clausen (red.) Kvantitativ analyse med SPSS (2. utg.). Trondheim: Tapir Akademisk Forlag.
Øverbye, Einar (2017) «Er selektivisme bedre enn universalisme i velferdspolitikken?». Norsk sosiologisk tidsskrift, 2 (1), 41–57.
Vedlegg 1: Mer om flernivåanalyse
Konseptuelt kan metoden og tolkningen av estimatene i en flernivåanalyse sammenlignes med vanlig lineær regresjon. En hovedforskjell er imidlertid at residualene beregnes for hvert nivå som spesifiseres i modellen, som illustrert i siste kolonne i tabell v1 (Strabac 2012). Disse nivåestimatene benevnes som random effects og kan komme i tillegg til andre uavhengige variabler, kalt fixed effects. Random effects tillater at den avhengige variabelen har ulikt gjennomsnitt for hver enhet som er definert i nivåene, slik at dette ikke påvirker den estimerte effekten (stigningen i koeffisienten) fra forklaringsvariablene. I artikkelen er vi hovedsakelig opptatt av hvordan den uforklarte variansen fordeler seg på nivåene i «tomme» modeller, altså modeller uten fixed effects. Vi starter med modeller uten forklaringsvariabler, for deretter å se noe nærmere på modeller med forklaringsvariabler.
Fordelingen av den uforklarte variansen mellom nivåene estimeres ved hjelp av intraklassekorrelasjoner (ICC). Det er en beregning av hvor stor andel av den uforklarte variansen i modellen som kan tilskrives hvert nivå (Mehmetoglu og Jakobsen 2017). Andelen oppgis vanligvis i prosent.
Flernivåanalyse må ikke benyttes selv om dataene kan tillegges en hierarkisk struktur. For modellene i Tabell 3 er det først og fremst i de sistnevnte modeller at det kan være nyttig å benytte flernivåanalyse. Dette indikeres ved at likelihood ratio (LR)-testen (StataCorp 2017a) er signifikant. Det kan tolkes som at den vanlige lineære regresjonens forutsetning om at restleddet er uavhengig, er brutt og at det er mer passende å benytte flernivåanalyse. Med en så lav ICC som her, ville det trolig også vært forsvarlig å gå videre med en vanlig lineær regresjonsmodell med robuste standardavvik dersom hensikten med analysen kun er å avklare effektene av uavhengige variabler (Mehmetoglu og Jakobsen 2017, s. 203).
Empirical Bayes
I flernivåmodellen fremkommer først og fremst den totale variansen mellom nivåene. Vi kan også beregne gjennomsnittsverdier for bestemte enheter på det enkelte hierarkiske nivå. Disse sistnevnte beregningene kalles empirical Bayes eller best linear unbiased prediction (BLUP), og kan være nyttige for å studere eller illustrere betydningen av bestemte enheter på høyere nivåer (StataCorp 2017b; Snijders og Bosker 2012; Steenbergen 2012). Empirical Bayes kan også benyttes til å illustrere forskjellene i det enkelte nivås betydning ved flernivåanalyse sammenlignet med vanlig lineær regresjon (se Snijders og Bosker 2012, s. 68). Vi gir et eksempel på dette i figur 1.
